Automating Information Extraction from Financial Reports Using LLMs
Published in Aalto University Master's thesis in Data Science, 2024
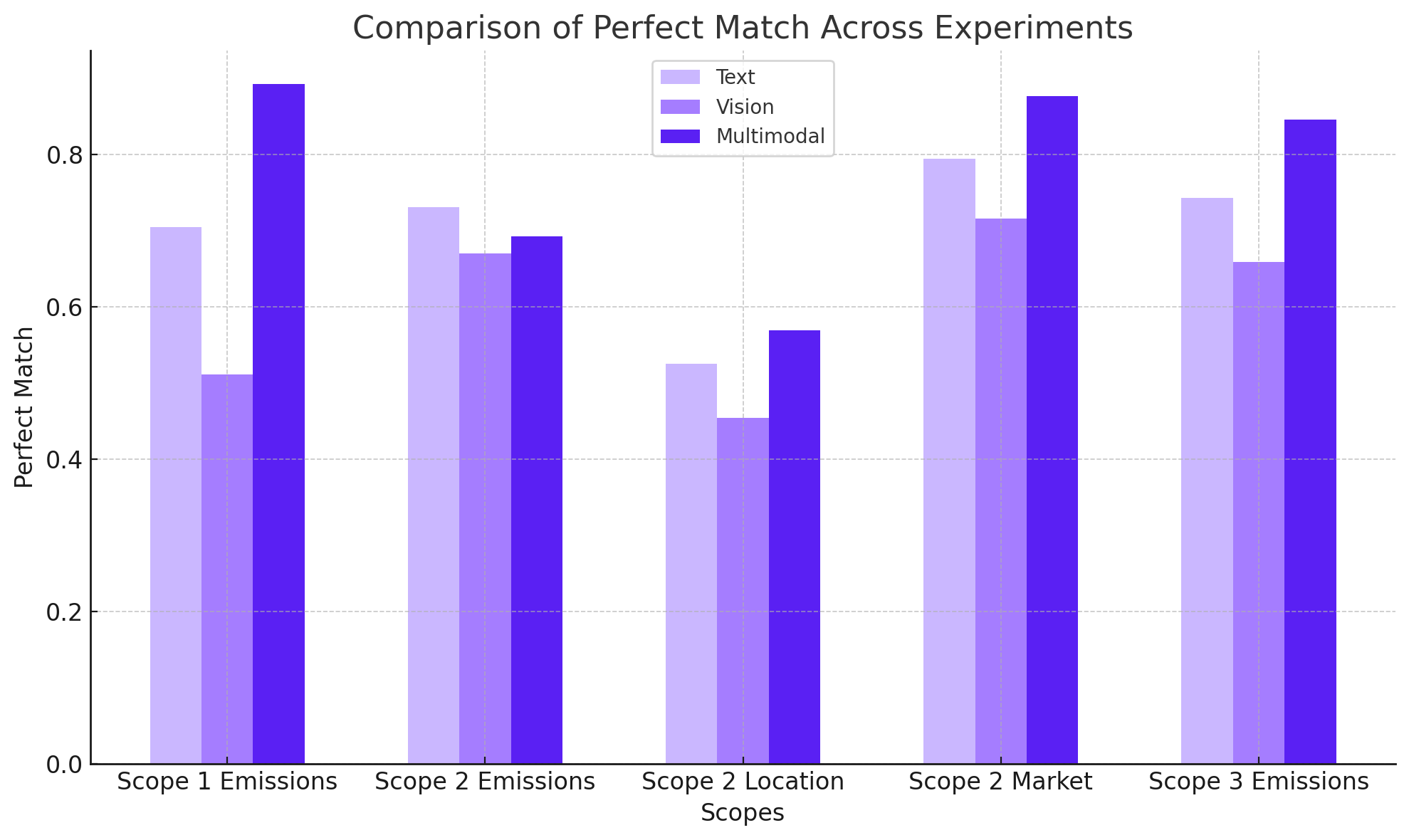
The study’s findings underscore the possibility of using the three approaches according to the nature of the dataset having a more confident usage when applying the combined multimodal approach in Document AI, particularly in format-agnostic scenarios such as the one presented in this study. The thesis also identifies challenges, such as the ambiguity in sub-indicators under Scope 2 emissions, and the importance of examining the tolerance for errors in the context of the application, where residuals can be acceptable or make the system completely unusable. This work contributes to the growing field of DocumentAI, offering insights into the capabilities and limitations of LLM for financial report analysis, and suggests pathways for future advancements in automated information retrieval systems.
Download here