Senior AI Engineer · Florianópolis, Brazil
Building reliable AI products from research to production.
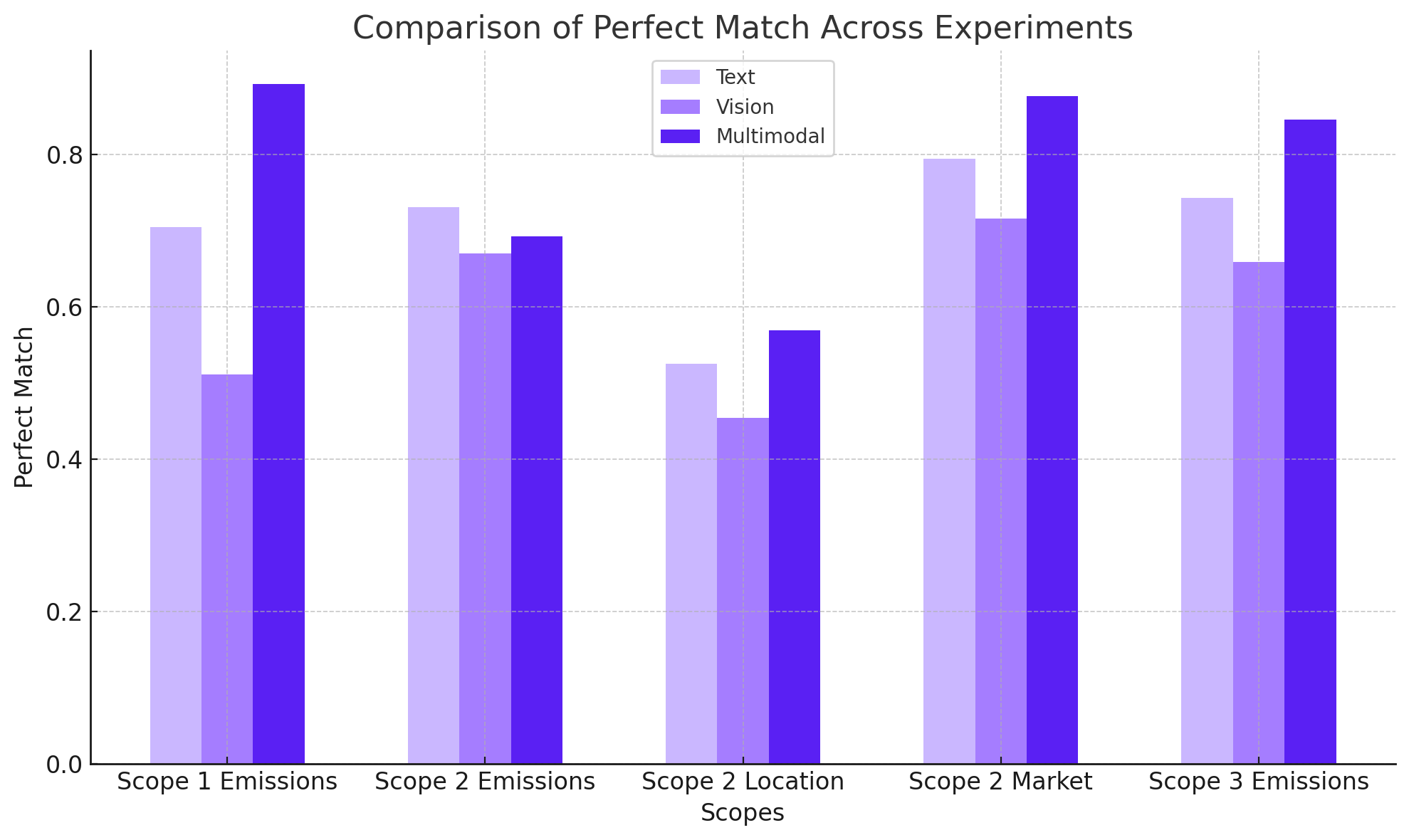
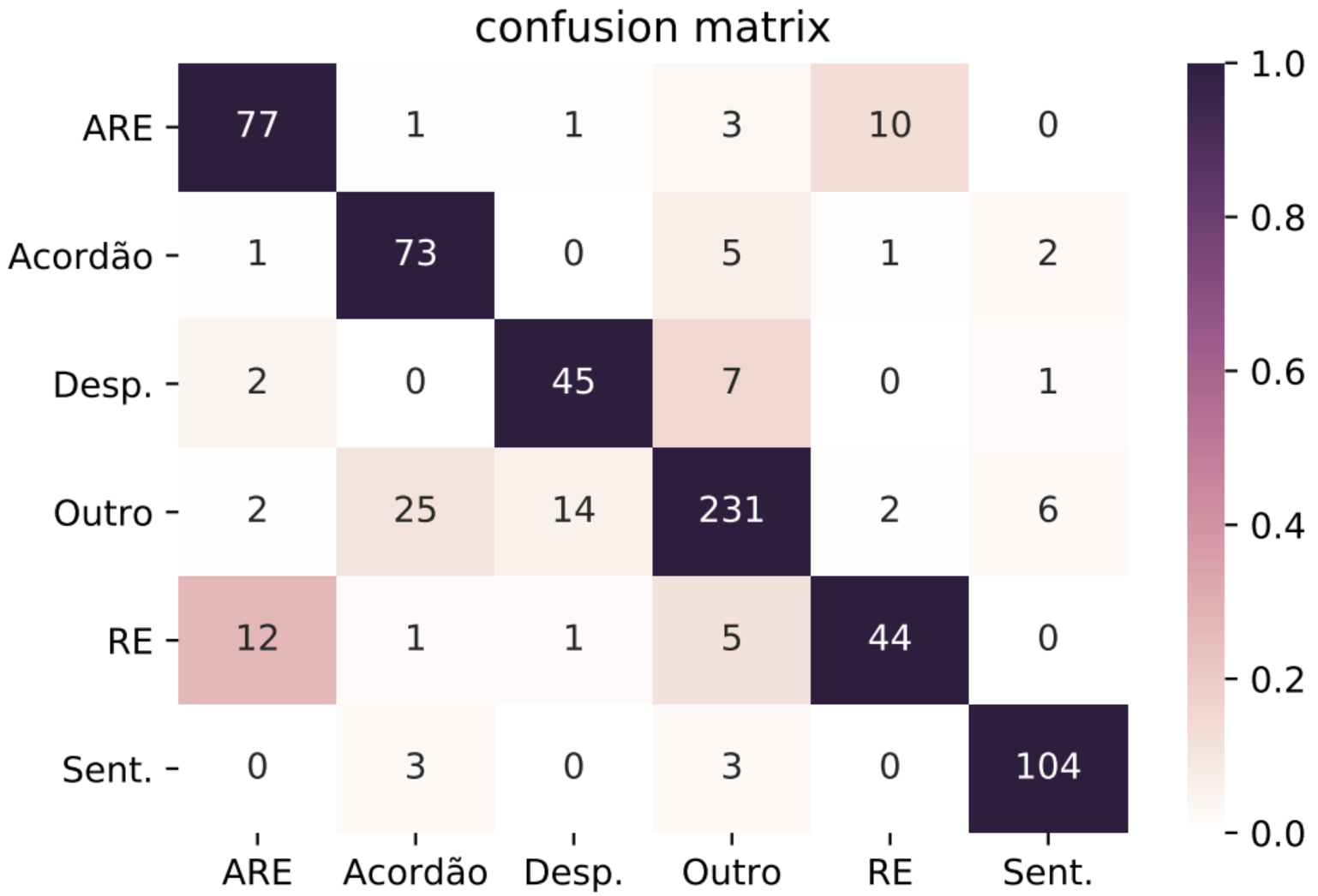
I turn complex data and machine-learning problems into useful software, backed by seven years of industry experience and a double master's degree in Data Science and AI.
Contact me- 7+ yearsAI & software
- Double MSc in Data Science & AIAalto University & TU Eindhoven
- Global experienceBrazil, US, Europe & remote teams
Award

Facebook F8 Hackathon Finalist
Top 8 out of 55 teams in San Jose, including a project pitch to Mark Zuckerberg.