Music Embedding Clustering
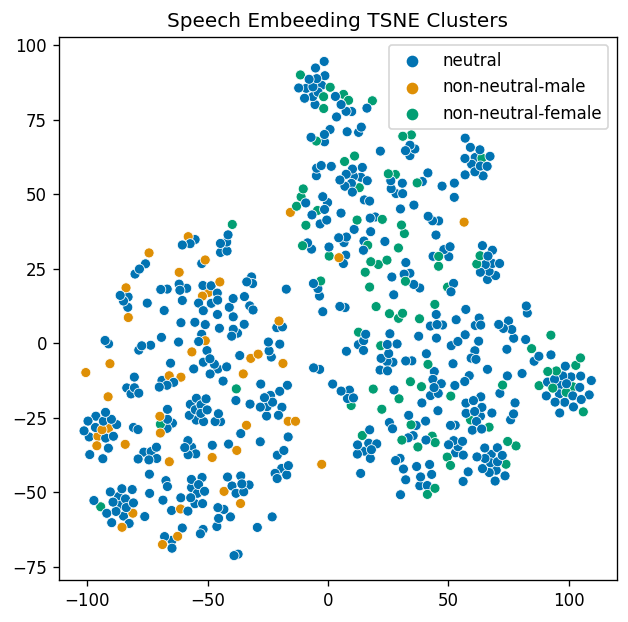
Music Embedding Clustering Using a Pretrained Speaker Verification Model. Can a model trained for speaker verification separate songs from different bands?


Music Embedding Clustering Using a Pretrained Speaker Verification Model. Can a model trained for speaker verification separate songs from different bands?
This task aims to motivate research for SER in our community, mainly to discuss theoretical and practical aspects of SER, pre-processing and feature extraction, and machine learning models for Portuguese.
Published in Unofficial Publication, 2018
Shallow decision trees are weak classifiers that can be combined to create a robust predictive model. Ensemble methods have benefits over a simple decision tree like reducing bias, over-fitting and accuracy improvement. This study has the purpose to study the state-of-art of boosting trees techniques and its applications and analyse qualitatively what has been published on boosting methods. We have searched on IEEE, Scopus, ACM and Elsevier repositories with a string derived from technique PICO. We found a total of 102 papers, and after applying our criteria we got 47 papers. We summarized the methods of gradient boosting decision trees for classification and regression problems. We analysed the algorithms XGBoost, LightGBM, CatBoost, LambdaMART in different published scenarios. We have classified the found papers in the subcategories: business, new method, civil engineering, network security, health, model improvement. We conclude that boosted tree-based algorithms is a field of research in exploration, and development of new techniques.
Published in The Tenth International Conference on Forensic Computer Science and Cyber Law, 2018
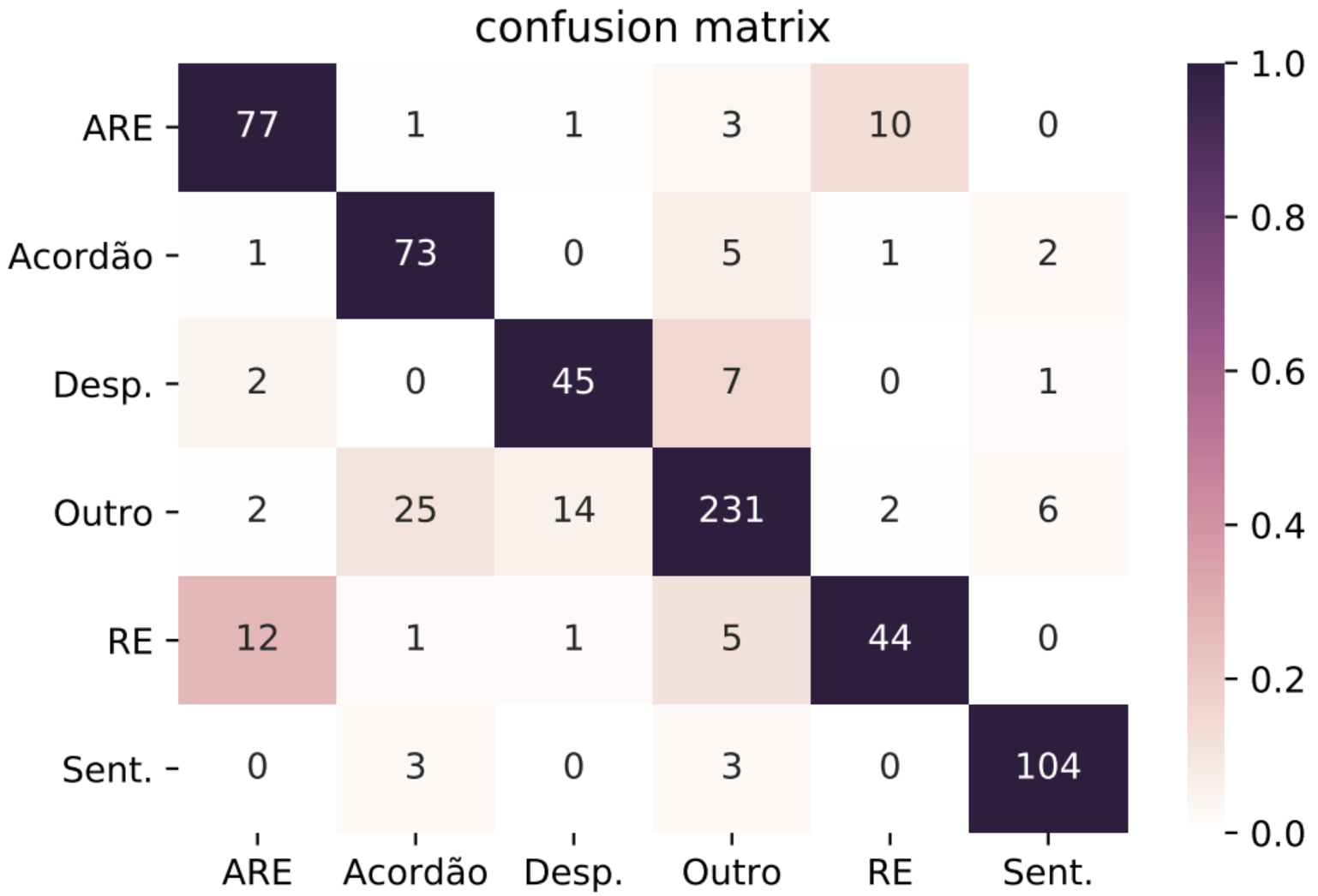
The Brazilian Court System is currently the biggest judiciary system in the world, and receives an extremely high number of lawsuit cases every day. These cases need to be analyzed in order to be associated to relevant tags and allocated to the right team. Most of the cases reach the court as single PDF files containing multiple documents. One of the first steps for the analysis is to classify these documents. In this paper we present results on identifying these pieces of document using a simple convolutional neural network.
Published in Machine Learning for Developing World: Achieving Sustainable Impact Workshop Proceedings NIPS, 2018
The Brazilian court system is currently the most clogged up judiciary system in the world. Thousands of lawsuit cases reach the supreme court every day. These cases need to be analyzed in order to be associated to relevant tags and allocated to the right team. Most of the cases reach the court as raster scanned documents with widely variable levels of quality. One of the first steps for the analysis is to classify these documents. In this paper we present a Bidirectional Long Short-Term Memory network (Bi-LSTM) to classify these pieces of legal document.
Download here
Published in Universidade de Brasília Software Engineering Bachelor Thesis, 2021
Context-Dependent Probabilistic Prior Information (CoDePPI), is a better prior information extraction algorithm for Magnetic Resonance Imaging (MRI) reconstructions with the use of the Compressed Sensing (CS) theory. Our method CoDePPI takes advantage of motion information across frames in a dynamic MRI to weigh the confidence that the extracted positions are effectively part of a support structure, that is, reducing the noise introduced by applying prior information.
Published in International Symposium on Intelligent Data Analysis, 2023
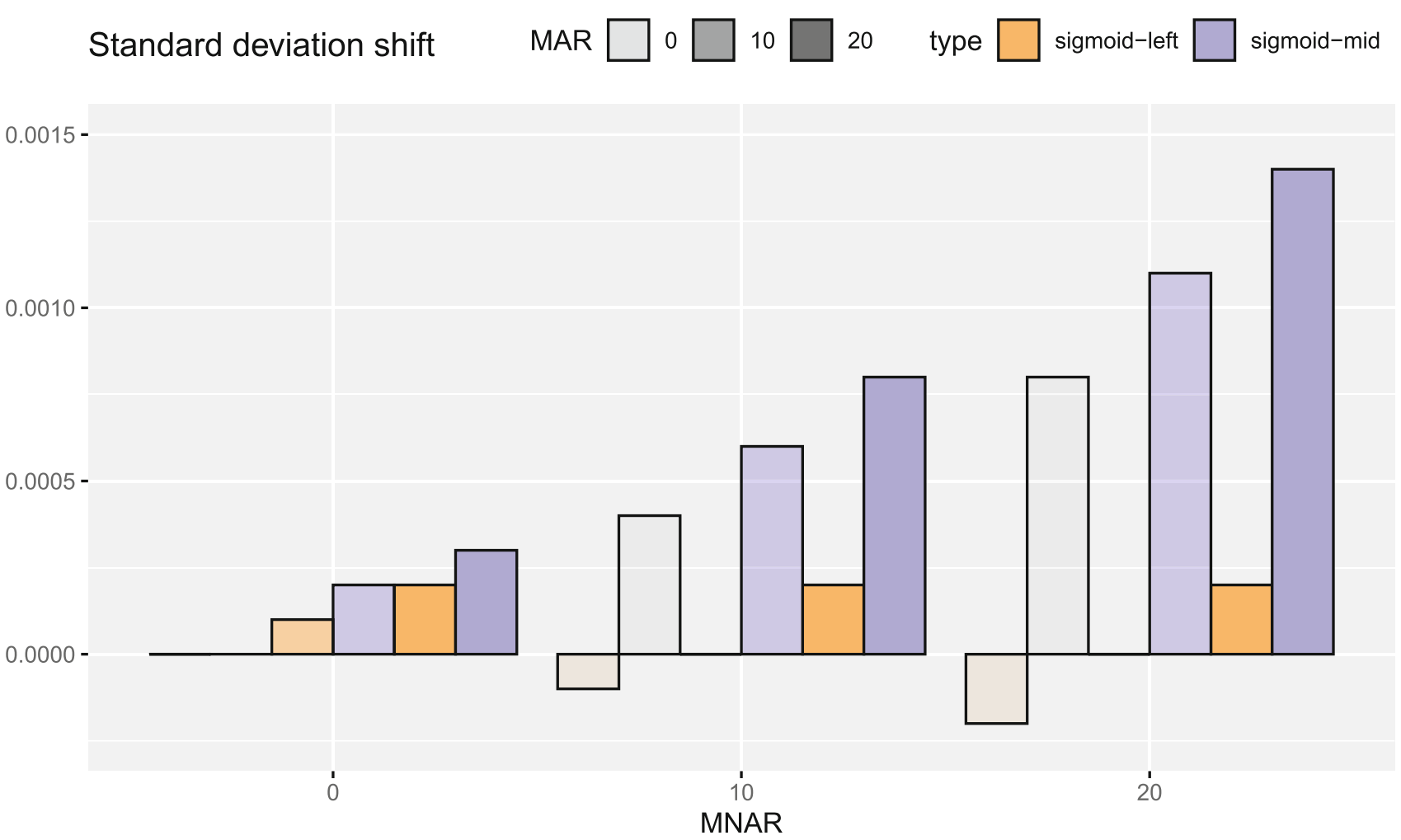
A straightforward approach to handling missing values is dropping incomplete records from the dataset. However, for many forms of missingness, this method is known to affect the center and spread of the data distribution. In this paper, we perform an extensive empirical evaluation of the effect of the drop method on the data distribution. In particular, we analyze two scenarios that are likely to occur in practice but are not often considered in simulation studies: 1) when features are skewed rather than symmetrically distributed and 2) when multiple forms of missingness occur simultaneously in one feature. Furthermore, we investigate implications of the drop method for classification accuracy and demonstrate that dropping incomplete records is doubtful, even when test cases are dropped as well.
Download here
Published in Aalto University Master's thesis in Data Science, 2024
The study’s findings underscore the possibility of using the three approaches according to the nature of the dataset having a more confident usage when applying the combined multimodal approach in Document AI, particularly in format-agnostic scenarios such as the one presented in this study. The thesis also identifies challenges, such as the ambiguity in sub-indicators under Scope 2 emissions, and the importance of examining the tolerance for errors in the context of the application, where residuals can be acceptable or make the system completely unusable. This work contributes to the growing field of DocumentAI, offering insights into the capabilities and limitations of LLM for financial report analysis, and suggests pathways for future advancements in automated information retrieval systems.
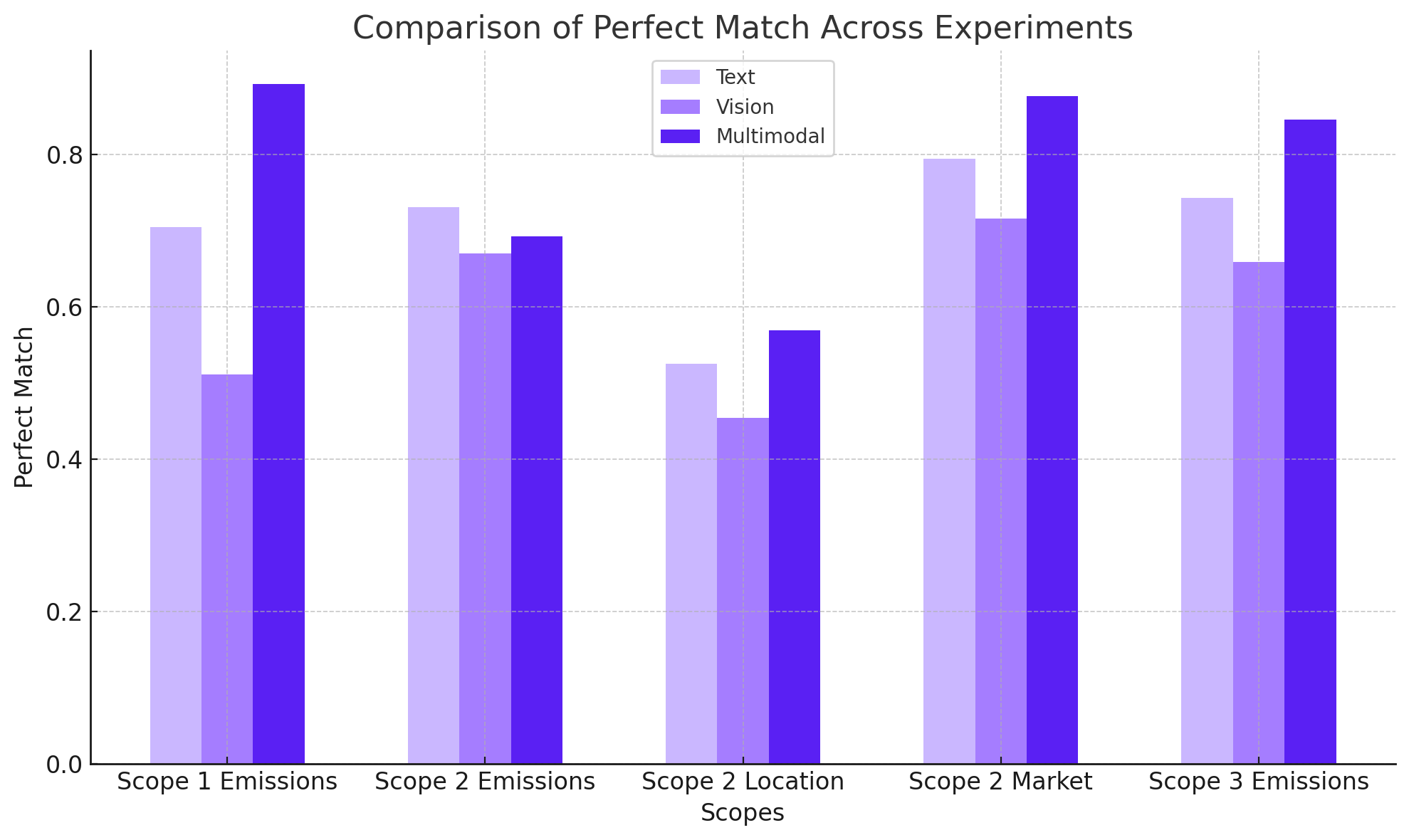
Download here
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.